The crawl stats report is a section within Google Search Console that gives you information on how Google is crawling your website. It shows how many requests for content to your servers were made, what those responses were, what file types and some other details. I like to think of it as a very light version of server log analysis, which misses out some key detail, but also gives some helpful insight that server logs do not.
It looks like the below – and in this guide, I’m going to talk you through what you can see in there, what it all means and what you should be looking for to gauge how Google is treating and responding to your site.
How does crawling work?
Google crawls through the internet as if it were a web – following internal links to URLs between pages on a website, and from one website to another. For a full breakdown of crawling, rendering and more – read my guide here – but for the below, we’re going to be looking at Google’s crawl stats report available to you in Google Search Console.
What is crawl budget?
I’ve written a full guide on crawl budget here, but as a reminder, crawl budget is a concept referring to how much resource Google will allocate to crawling and understanding your site.
If you are a small-time site with not a lot of pages, not a lot of backlinks, authority or traffic – Google will not spend a lot of time crawling you.
If you are Amazon with millions of pages, backlinks and visitors, Google will spend a lot of time and resource making sure their understanding of your site (and their ‘index’ of it) is up to date and comprehensive.
If you are launching a 1 million page site overnight from a base of zero, you cannot expect Google to instantly crawl all 1 million pages – they don’t know you yet, and their effort will scale proportionately with your site.
Crawl budget efficiency (say Google has a finite amount of resource to devote to your site) refers to whether they are using that crawl budget to look at important pages, or wasting them on irrelevant and duplicated parameter URLs whilst not revisiting your core product pages often enough.
Issues like this can be somewhat identified in the crawl stats report, other reports in GSC (e.g. last crawled information) and comprehensively answered through server log analysis. As per the below, ‘crawl budget’ is not an issue for 95% of websites, particularly if you are below 1-10k URLs, but it can be a challenge at enterprise level.
Crawl Stats vs. Server Log Analysis
Server log files (read my separate guide here) are server-level records of every single request that was made to your website server. You can filter these out for Googlebot user agent to see what pages and resources Google is trying to crawl on your site, and monitor a range of other elements.
Server log files are not really crucial unless you have a website in the scale of 100k+ URLs, and are not an area that needs deep investigation for 95% of websites I come across.
Google Crawl Stats report is a lighter version of their crawl behaviour (or ‘server logs’) that is importantly accessible to everyone with a domain-level GSC property – and if you read my guide on server logs, you’ll know that they’re quite often not easy to come across.
What can I use the crawl stats report for?
The crawl stats report can help you identify at a high level how Google is crawling your site and any general issues they may be coming across. Read through the below sections for an explanation of what you might expect to see, and what it might mean.
How to access the crawl stats report?
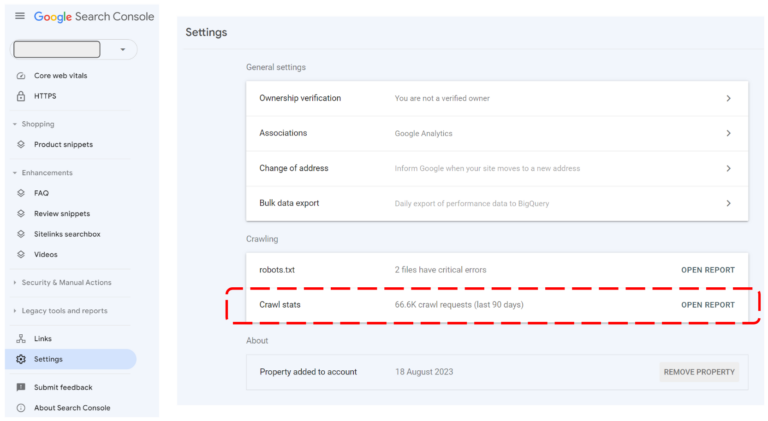
To access the crawl stats report, you need to go into the Settings menu on the left hand navigation (which is a strange location I agree, and it should probably be straight on the LHS menu itself!). From here, click on crawl stats > open report under the Crawling section.
What am I seeing?
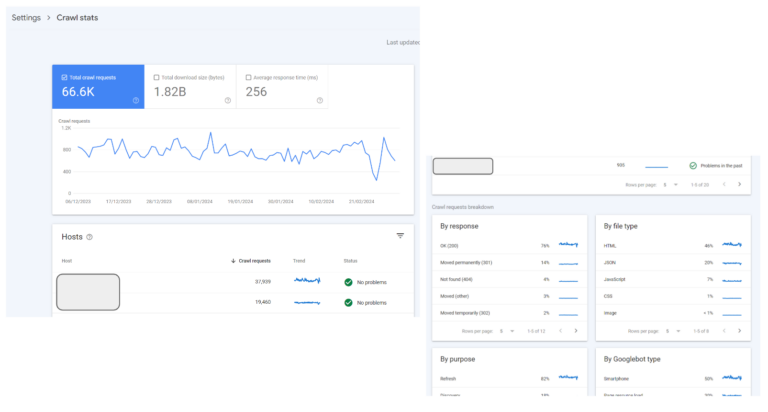
When you open up the report you will see this main ‘dashboard’ with several charts and tables. Below is an explainer of each, and some guidance on what you should expect to see in each of them.
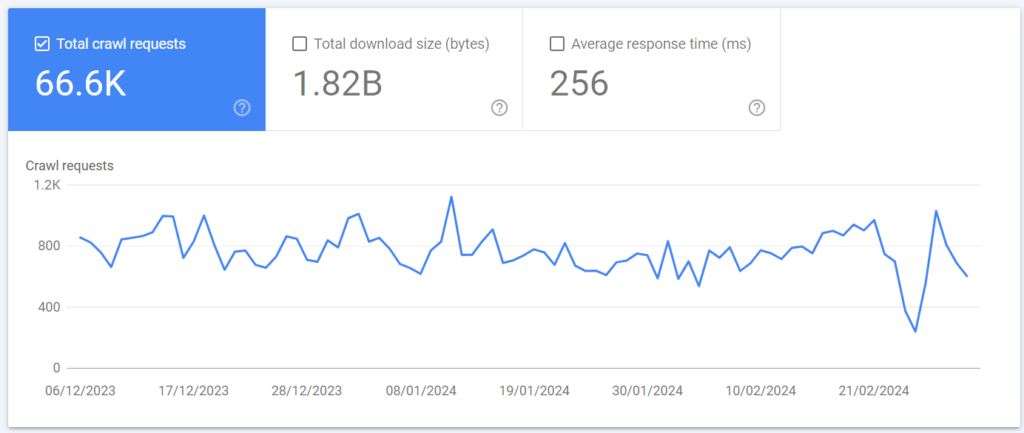
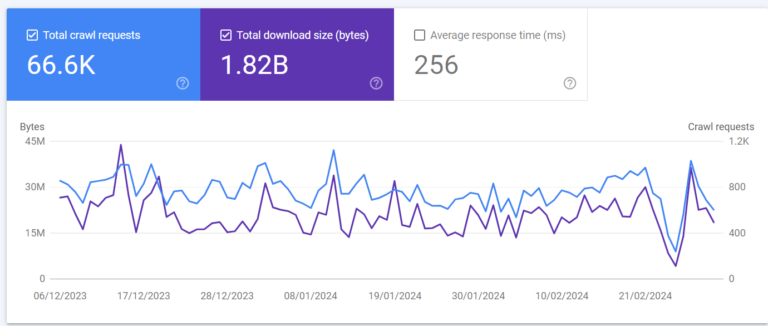
Requests
Requests is the number of individual resource requests made by Google in the last 90 day period. This is not the number of pages crawled – as you will see by the below sections, those requests are split across different file types. This example with 66.6k requests and 46% of those being HTML files, we could roughly translate that to 30.6k URLs being crawled over the last 90 days.
For this site which has just under 600 pages, that gives us confidence that Google is likely going to be crawling all key pages frequently enough.
Note that as per the below section on file types and as you click through to explore them, HTML files will not always be the perfect main URLs you want – Google might be discovering other parameter versions of them to crawl, strange internal linked versions and more. Server log analysis can help you truly understand this (and also understand how often main pages are being crawled).
Size
This shows the total size of content downloaded by Googlebot (in bytes) as part of their crawling activity, and if you select this and crawl requests, you’ll see that they usually track pretty closely. There is no clear rule from Google that their crawl budget is determined based on number of URLs, or total size of downloaded content, so there’s not much insight that you can see here. Nonetheless, if you are making changes and reducing image file sizes, streamlining code bases or other elements of your site then you may be able to see a corresponding change in the download size.
For this site we can see it is fairly stable and consistent – aside from a short dip down in Googlebot crawling activity in February.
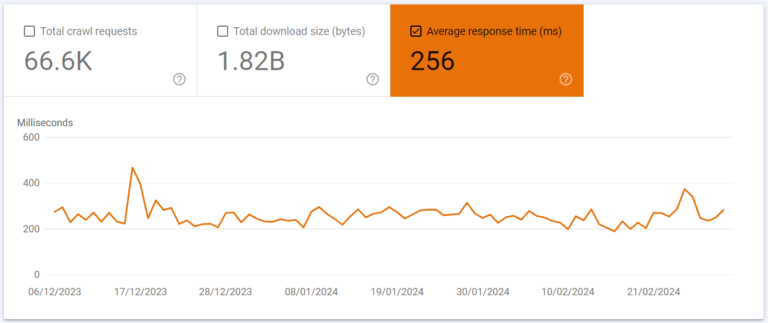
Response Time
Response time is the time it took your server to respond to Googlebot’s request for a resource. Selecting this on the graph will give you an idea of whether your hosting is fast, consistent, has issues, potentially got slowed down on a super busy day for website activity. Note that this is not your site speed, just the time for the initial request / response for content (rendering and putting together the DOM, amongst other things, determines your ‘site speed’ – click here to read more).
Again as we can see, this site is fairly stable and consistent in response times. Note that unlike Core Web Vitals, there is no specific good / needs improvement / fail scoring here.
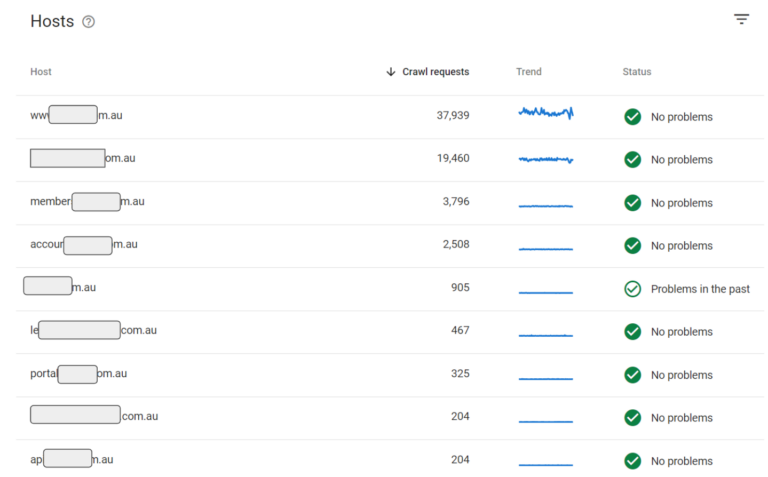
Host status details
The host status section refers to whether any of the hosts (read: subdomains or properties) had issues with connectivity and didn’t respond in time to Googlebot requests. 99% of the time you should be fine here (as long as you have stable hosting and server operations), Google will occasionally flag that you ‘had problems in the past’ but often this is flagged from one day when your server failed a Google request for whatever reason. This is a good section to monitor, but generally nothing to worry about.
As per the below – this website has multiple subdomains and properties, however nearly all of them are clear and showing no problems.
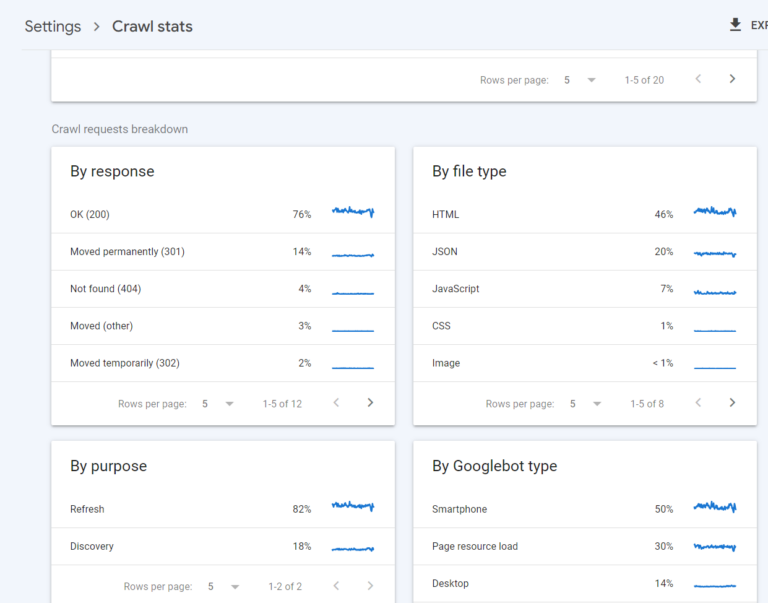
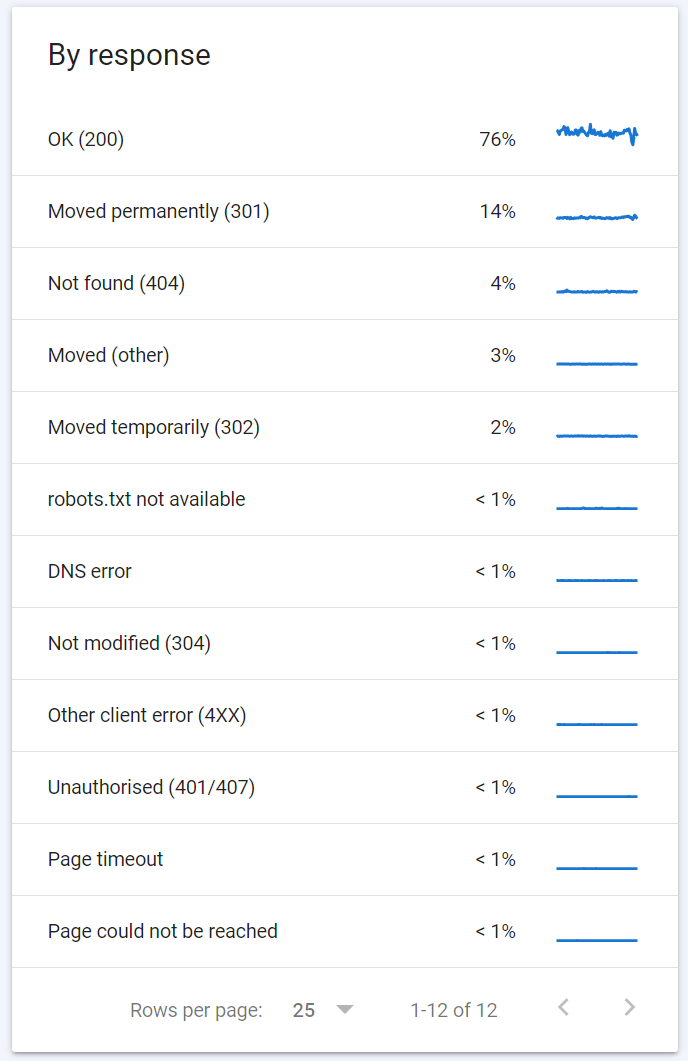
Response type
The response type shows the response code that was returned to Googlebot from the server. I have a full guide on server response codes here, but the short version is that you would hope and expect that a majority of URLs are returning a 200 response code (70-80% would be ideal).
Redirects (301 / 302) are expected, particularly for sites that have been around for a while and gone through several changes and technical elements requiring redirects, so it’s perfectly fine to see Google checking old URLs and revisiting them (yes, even if it is from 2 years ago – Google doesn’t want to let go sometimes!).
If you have a very high proportion of 30X URLs, it’s worth checking whether there are redirect chains that might be causing this (e.g. if one URL redirects to another to another to a final one – triggering 4 URL requests that Google has to follow, 3 of which will be 30X).
URLs that are 404 (not found) again are going to be expected in small numbers, but it’s worth exporting this list (or at least the 1000 that you can) and implementing redirects to relevant current URLs so that Google minimises the time wasted and dead ends on these URLs, and passes on all relevant page value.
Finally there will be some errors and other miscellaneous codes – in small percentages 1-2% these are fine, if you have a large volume of 500 server errors then it likely indicates some issues to investigate.
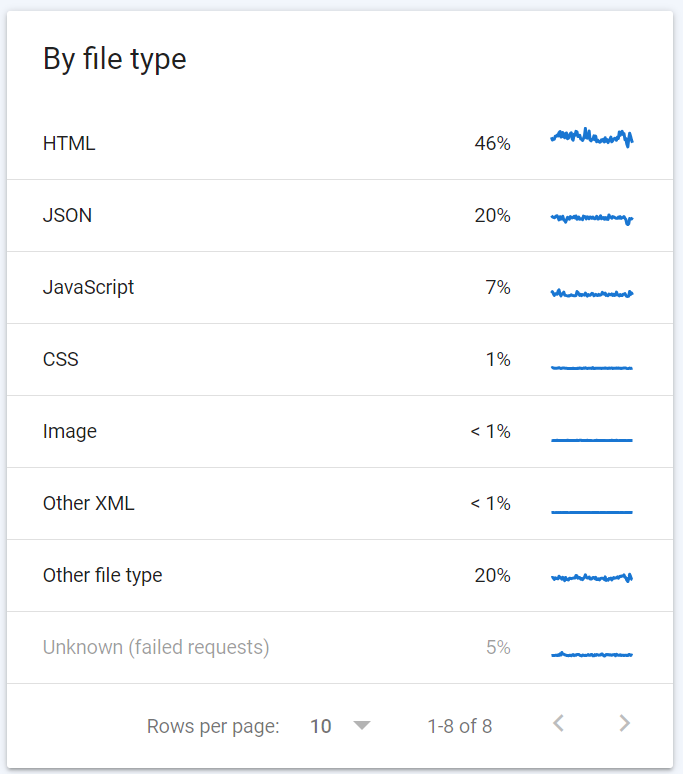
File type
The file type gives you an overview of what file type Google is requesting. There is a pre-set list that they will show here (the main ones being HTML, JSON, Javascript, CSS, Image, PDF) with other things being grouped under ‘Other’.
HTML is generally expected to be the largest component, but it really depends on the website as to what % this might be, and what the other ratios are.
Websites that have consistent JS files (as opposed to unique ones for each page) will see low percentages of JS file type requests (especially if Google is caching a version for themselves to use).
However, a high volume of HTML requests and a low number of JS requests could indicate that Google is not rendering enough Javascript on pages and is missing out on key information – all areas for further technical investigation!
The ‘Other’ section is often things like fonts, API requests, or files in formats not per the above. Looking at what shows up in this section can give hints about directives that may need implementing and tightening, but often it’s not critical.
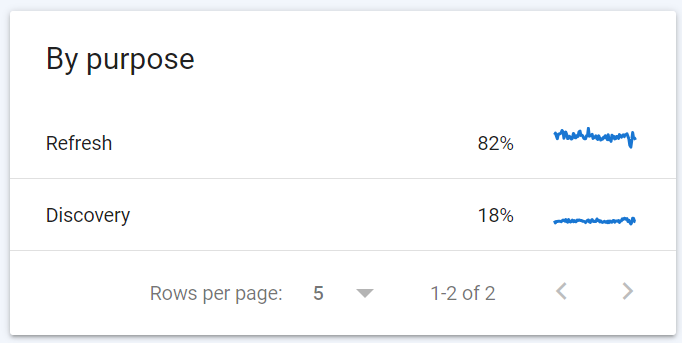
Purpose
The purpose section shows just two options – refresh, or discovery.
Refresh is Google revisiting a resource (whether URL, image or other) that they already know about and have in their index.
Discovery is a brand new resource they haven’t crawled before.
I would generally expect refresh to be around 80% of Google’s crawling, and discovery another 20%. If you have numbers way off from this, it may be that you’re scaling fast and constantly adding or changing a lot of new elements on the site, but also could mean that Google is getting stuck into parameter crawling and infinite numbers of URL options – in which case you should get your technical SEO and some crawling directives under control!
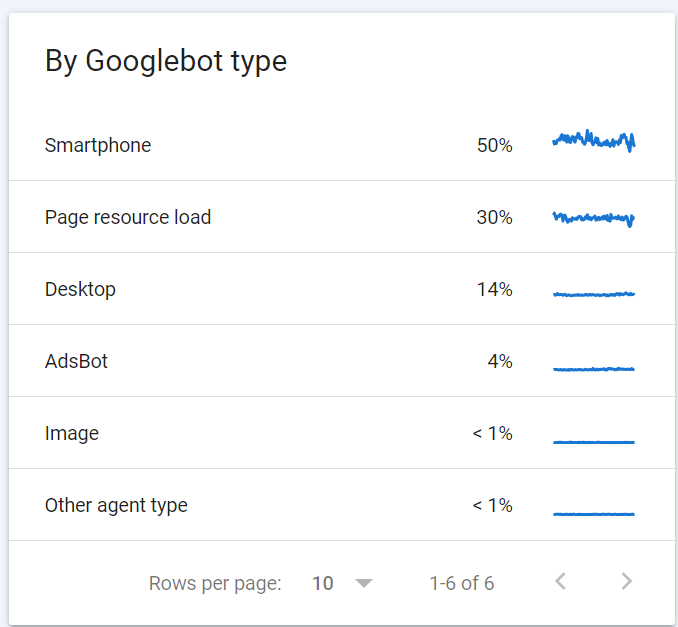
Googlebot Type
Here you will see the % split breakdown between the different Googlebot types.
As most crawling is now mobile-first, I would expect smartphone to be the highest proportion here (As per the example below, 50%).
Page resource load is generally the next largest (30% for this site), and refers to the secondary ‘rendering’ process of a page (e.g. when javascript, CSS or other files are requested).
Desktop googlebot may still be occurring (14% for this site example) – just in smaller numbers to Mobile usually.
Finally, Ads bot will crawl the site if you are running ads (I believe paid search ads, display ads etc.) more as a means of checking / confirming the page experience that the ads are sending to. Percentages here are generally quite low – less than 5-10% I would expect. There’s also always some ‘Other’ under 1% that exists – and nothing you really need to worry about.
Additional Notes
The crawl stats report will not give you a list of every single URL and timestamp that Google comes to crawl your site. As with a lot of GSC reports and features, there is a limit of 1000 rows so whilst you can export some elements and get some bearings on things to look at, you will never be able to export a full list of 404 URLs for example.
Final Summary
Hopefully this has equipped you with the knowledge you need to understand what’s in Google’s Crawl Stats report, what it can help you understand and diagnose, and steer you in the direction of further technical SEO investigations.
If you need some help with your site’s technical SEO – get in touch with me below! I’ve run plenty of complex technical projects for massive SaaS, eComm, enterprise and franchise brands, and can help you get the most out of your site – so that Google loves it, and ranks it higher in search!